
ウェブブラウザは通常人の手で操作しますが、プログラムで動かすことができるのがSeleniumです。
Seleniumを使ったブラウザの操作はWebシステムの自動テストやスクレイピングに使われることが多いですが、それだけに留まらず応用範囲は多いと思われます。
今回はSeleniumを使ったブラウザの自動操作を試してみます。プログラミング言語はSeleniumと相性のよいPythonを使用します。スクレイピングをしようとするとBeautifulSoup等のライブラリを使う例をよく見ますが、できるだけシンプルに動作できるように導入するのはPythonとSelenium、WebDriverだけにとどめ、必要最小限のものだけで動作させてみます。
動作環境はWindows10で紹介しますが、Macでもほぼ同様の操作で実施できると思います。
まずはPythonをインストール
Pythonインストーラをダウンロード
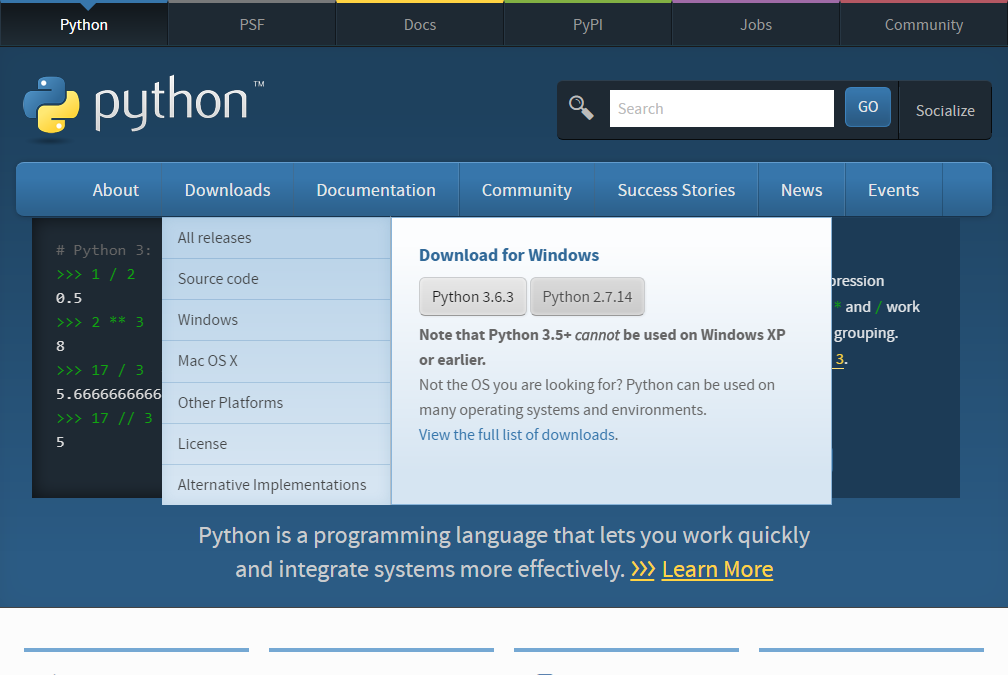
Pythonの公式サイトからインストーラをダウンロードします。
トップページの「Downloads」メニューから「Python 3.6.3」ボタンをクリックすると、インストーラがダウンロードできます。
Windowsの場合、執筆時点でバージョン3.6.3と2.7.14がありますが、ここではバージョン3系統を選択しました。
Pythonをインストール
ダウンロードしたインストーラを実行してPythonをインストールします。
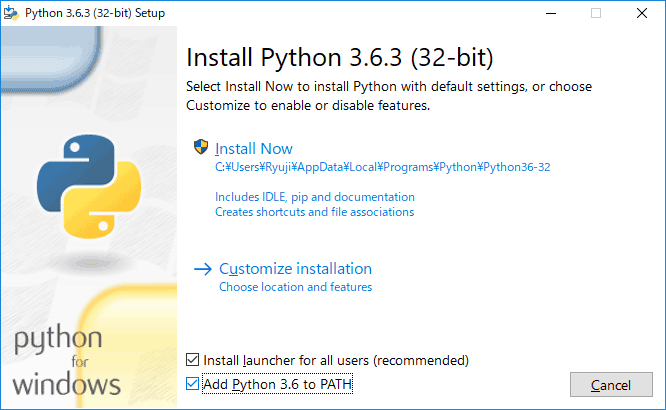
Add Python 3.6 to PATHにチェックを入れ、Install Nowをクリックします。
Add Python 3.6 to PATHを設定することで、後でPythonコマンドを使用するときにパスが通るようになります。この設定をしておかないとコマンドプロンプトからPythonを使うときに少し面倒になります。
自分でパスを設定したい方や、環境変数を汚したくない方は自分で後から設定すると良いでしょう。
あとはデフォルト設定でインストールを続けて問題ありません。
Pythonインストールの確認
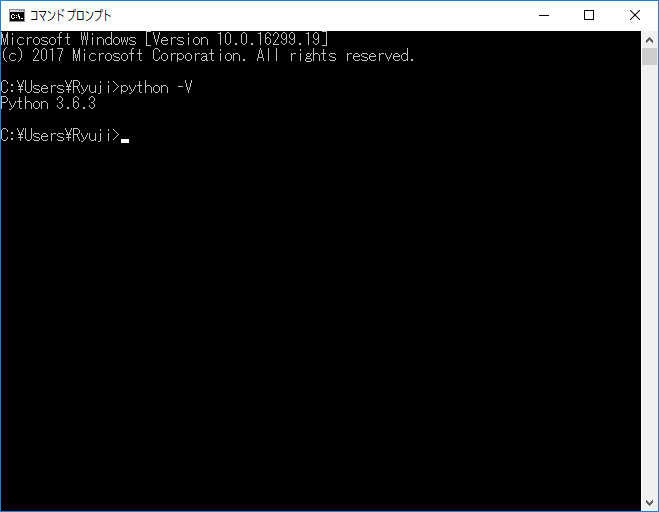
インストールできたかどうかを確認します。コマンドプロンプトを起動しpython --Vと入力します。
インストールされたPythonのバージョンが表示されればインストールできています。
Seleniumをインストール
次にSeleniumをインストールします。SeleniumはPythonのパッケージ管理システム「pip」を利用してインストールします。
コマンドプロンプトでpip install seleniumと入力します。
>pip install selenium
Collecting selenium
Using cached selenium-3.7.0-py2.py3-none-any.whl
Installing collected packages: selenium
Successfully installed selenium-3.7.0
WebDriverをインストール
Seleniumは操作するブラウザに対応したWebDriverと呼ばれるドライバが必要です。今回はGoogle Chromeを使ってウェブブラウザの自動操作をしてみます。
Chrome用のWebDriverをダウンロード
Selenium公式のダウンロードページからリンクしていってもよいですが、GoogleのChrome用WebDriverのサイトからダウンロードすると良いと思います。
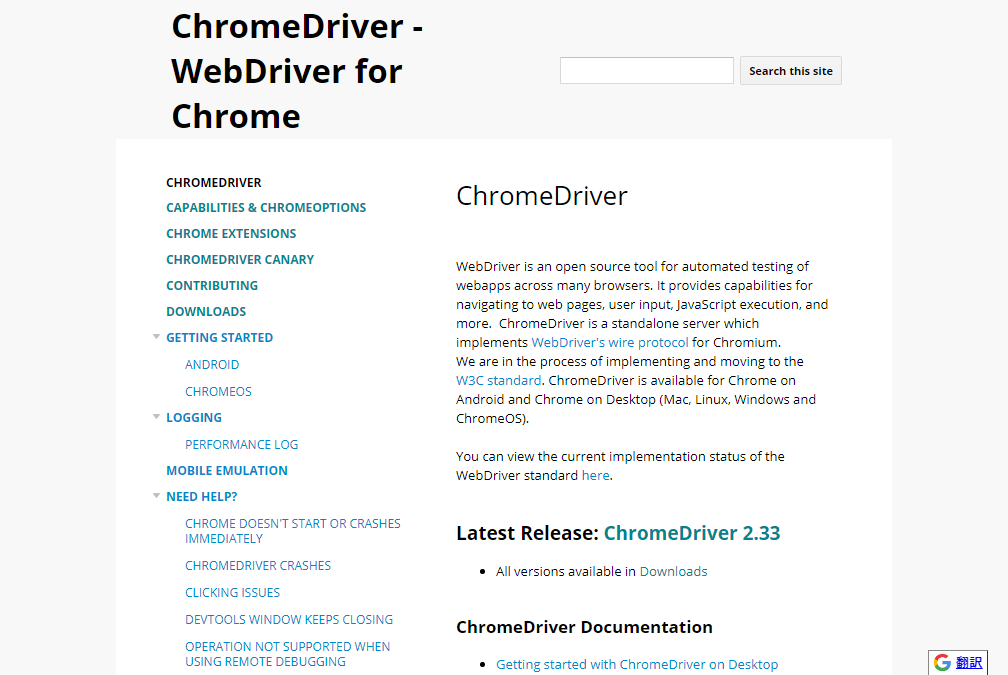
GoogleのChrome用WebDriverのサイトにアクセスし、「Downloads」からWebDriverをダウンロードします。このとき、使用するChromeのバージョンに対応したDriverをダウンロードする必要があります。
ドライバはOS毎に用意されていますので、Windowsの場合はWin32版をダウンロードします。
WebDriverを配置する
ダウンロードしたファイルはZIP形式になっているので、展開します。展開すると中にはexe形式のファイルが一つはいっています。このファイルをわかりやすい場所に置いてください。
ここではC:\driver\に置きます。
ブラウザの動作をプログラムする
ここまででブラウザを自動操作するための準備は完了です。あとはPythonでブラウザの動作をプログラムしていくだけです。次のプログラムをファイル名sample.pyで作成し、動作させてみます。
from selenium import webdriver
driver = webdriver.Chrome("c:/driver/chromedriver.exe")
driver.get("http://www.yahoo.co.jp")
プログラムの解説
1行目:webdriverモジュールをインポートしています
2行目:WebDriverのパスを指定してChromeを起動します
3行目:Yahooのページをブラウザで開きます
プログラムの実行
コマンドプロンプトでpython sample.pyと入力して実行します。
ChromeでYahooのページが開く動作が自動で行われます。
自動入力と自動クリック
上のプログラムはただURLを開いただけでしたので、次はYahooの検索ボックスに検索ワードを入力して検索するのを自動化してみましょう。
from selenium import webdriver
driver = webdriver.Chrome("c:/driver/chromedriver.exe")
driver.get("http://www.yahoo.co.jp")
elem_search_word = driver.find_element_by_id("srchtxt")
elem_search_word.send_keys("selenium")
elem_search_btn = driver.find_element_by_id("srchbtn")
elem_search_btn.click()
プログラムの解説
6行目は入力したいテキストフィールドの要素を取得しています。このページのHTMLソースを見ると、検索語を入力するテキストフィールドのIDがsrchtxtということがわかるので、find_element_by_idメソッドを使ってこの要素を取得します。7行目は取得した要素にsend_keysメソッドを使ってseleniumという文字を入力しています。同様にして8行目は検索ボタン要素の取得、9行目は検索ボタンをクリックする動作になっています。
この一連の操作はjQueryと非常によく似ています。まず操作対象の要素を取得し、その要素に対して操作をするという手順です。
要素を取得する方法はこの例ではIDから取得しましたが、classから取得するfind_element_by_class_name、jQueryと同じようにCSSセレクタで指定することができるfind_element_by_css_selectorなどが用意されてます。また、操作用のメソッドも用意されているので、これらを組み合わせればブラウザの動作を記述することができます。
使用できるメソッドは下記のサイトが参考になります。
公式:https://seleniumhq.github.io/selenium/docs/api/py/api.html
非公式(日本語):https://kurozumi.github.io/selenium-python/api.html
もう少しそれっぽいことをしてみる
先程のプログラムではseleniumで検索をする動作をしてみました。では次は検索した結果のURL一覧を取得してみましょう。
検索結果のURLはaタグに含まれるので、狙いのaタグのCSSセレクタを調べると#WS2m .w .hd h3 aでいけそうです。
ここで注意したいのが、このセレクタでは複数の要素が取得できるということです。find_elements系のメソッドを使うと複数の要素取得ができます。戻り値としては要素のリストが返ることになります。したがって、一つ一つのURLを調べるには、リストの要素を一つずつ繰り返し処理すればよいことになります。
from selenium import webdriver
driver = webdriver.Chrome("c:/driver/chromedriver.exe")
driver.get("http://www.yahoo.co.jp")
elem_search_word = driver.find_element_by_id("srchtxt")
elem_search_word.send_keys("selenium")
elem_search_btn = driver.find_element_by_id("srchbtn")
elem_search_btn.click()
elements_a = driver.find_elements_by_css_selector("#WS2m .w .hd h3 a")
for elem in elements_a:
url = elem.get_property("href")
print(url)
これを実行するとURLをprintしているので、取得したURLがコマンドプロンプトに表示されます。
>python sample.py
DevTools listening on ws://127.0.0.1:12379/devtools/browser/a7c1a0d6-2859-41a0-af71-18d0a8ffae61
https://qiita.com/edo_m18/items/ba7d8a95818e9c0552d9
https://codezine.jp/article/detail/10225
http://www.seleniumhq.org/
https://app.codegrid.net/entry/selenium-1
https://thinkit.co.jp/free/article/0705/2/1/
http://www.atmarkit.co.jp/ait/articles/1210/05/news104.html
https://www.ossnews.jp/oss_info/Selenium
https://github.com/SeleniumHQ/selenium
http://gihyo.jp/news/report/2017/01/1101
まとめ
Seleniumを使うとブラウザの自動操作が非常に簡単にできることがわかりました。システムの自動テストやスクレイピングに簡単に応用できそうです。
単純にスクレイピングしたりHTMLを取得して処理する場合は、Beutiful Soupを使う方法のほうが良い場合が多いようにと思いますが、ブラウザを実際に動作させるので単体テストにはSeleniumが良いなど、ケースバイケースで何をすべきか引き出しを多く持っておくことが大切だと思います。
Webスクレイピングの実例
スクレイピングをして以下のようなデータ調査を行いました。